
Making AI tools transparent for all users
Translating founder instinct into systematic measurement at an early-stage AI startup.
Role: User Researcher and Agentic Experience Researcher
Dates: August 2025 to present
Methods: Moderated interviews, behavioral observation, in-product surveys, prototype testing, A/B testing
Collaborators: Two engineering co-founders
Context
Header builds infrastructure for both humans and AI agents to follow the sources of content (newsletters, podcasts, YouTube channels, subreddits, RSS) and turn them into briefings shaped around a topic of interest with specific goals.
When I joined as the first researcher, the team had a working product, an engaged early-user community, and strong product sense from the co-founders. What it did not have was a systematic way to know when the product was difficult for someone who did not think like an engineer.
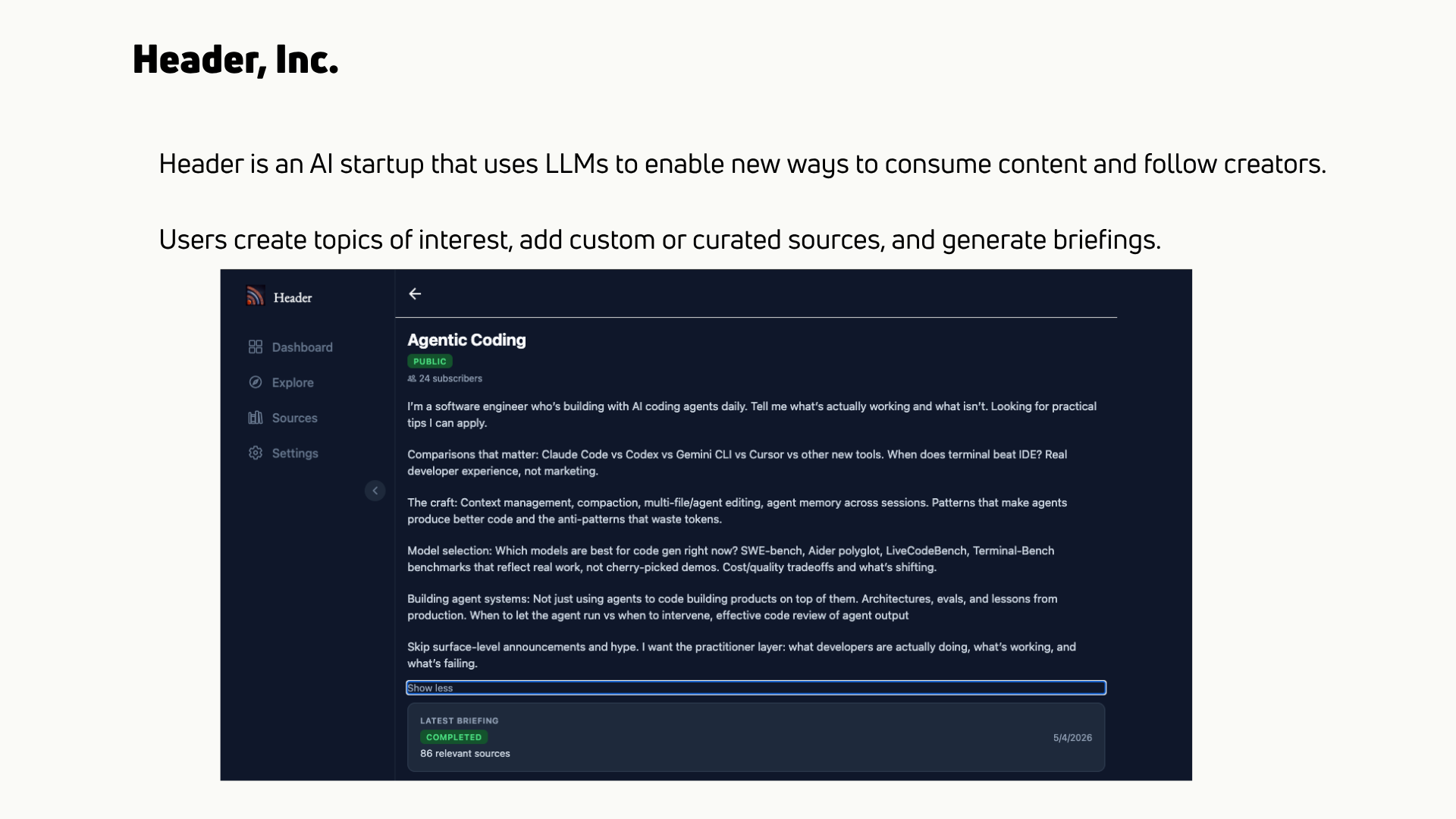
Situation
The early-user pool was small, technically sophisticated, and self-selected. They reported issues by talking to the founders directly; the founders responded by shipping. This worked at the scale of ten users. It would not work at the scale of a hundred, and it hid problems the early cohort never had: not knowing what an RSS feed was, not knowing how to write a productive prompt, not knowing how to evaluate whether a source would yield useful briefings.
There was no infrastructure for participant recruitment, no usability testing pipeline, and no shared definition of what “the product is working” meant.
The challenge
My charge was to figure out how to make people see value in the product and actually use it without getting confused or frustrated. The implicit success criteria were more users, higher use frequency from existing users, and a quality bar on briefings. Stakeholders were the two co-founders; we worked in a tight loop.
What I did
I started by widening the participant range. I ran moderated interviews and observations with users who varied substantially in AI working knowledge, programming background, and prior exposure to content-aggregation tools. The behavioral data was paired with in-product surveys (ratings on briefing quality and informativeness) and back-end logs (briefing creation success and failure, source-add attempts, generation frequency).
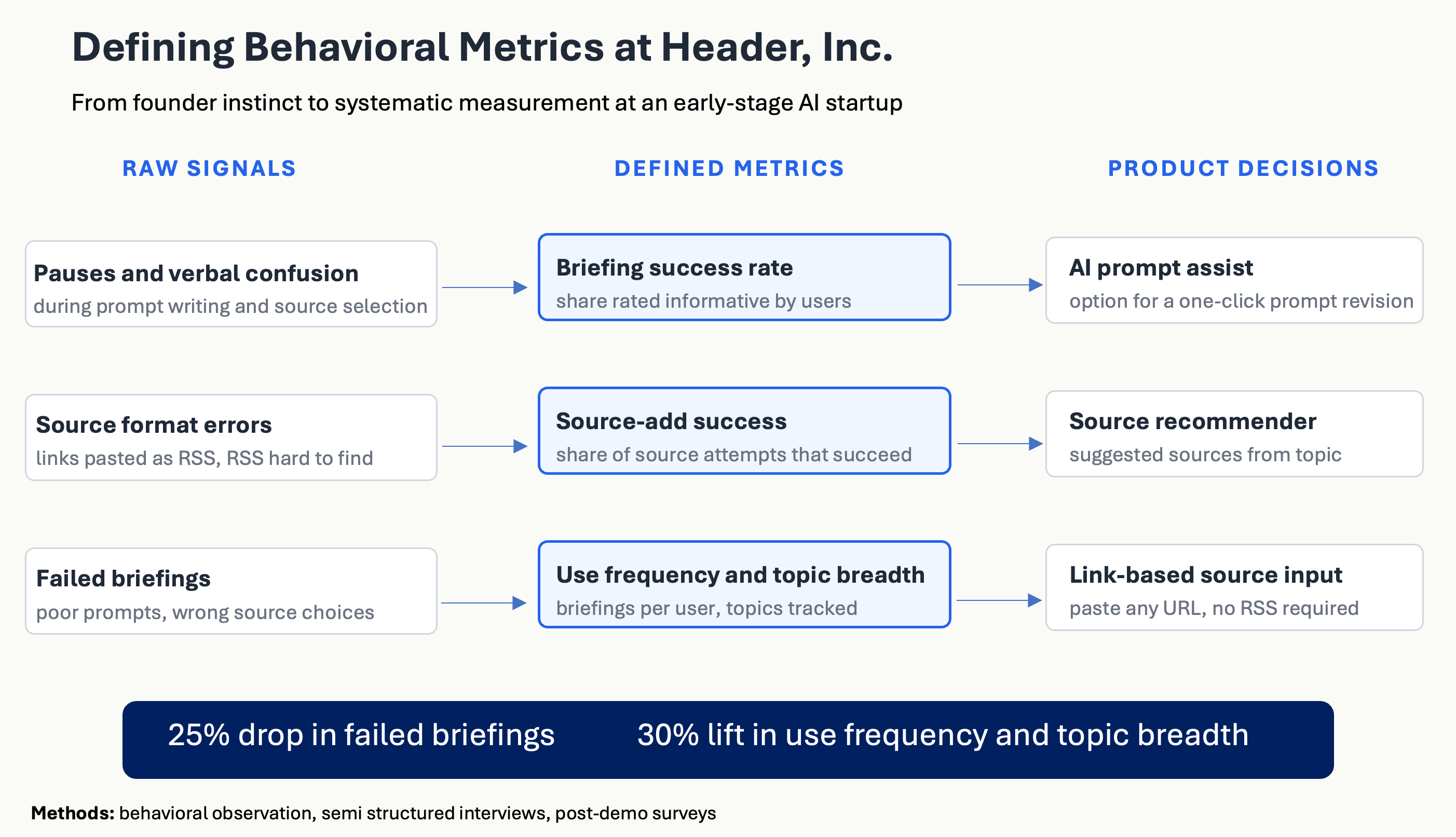
This combination surfaced three signal categories the founders had not been tracking systematically:
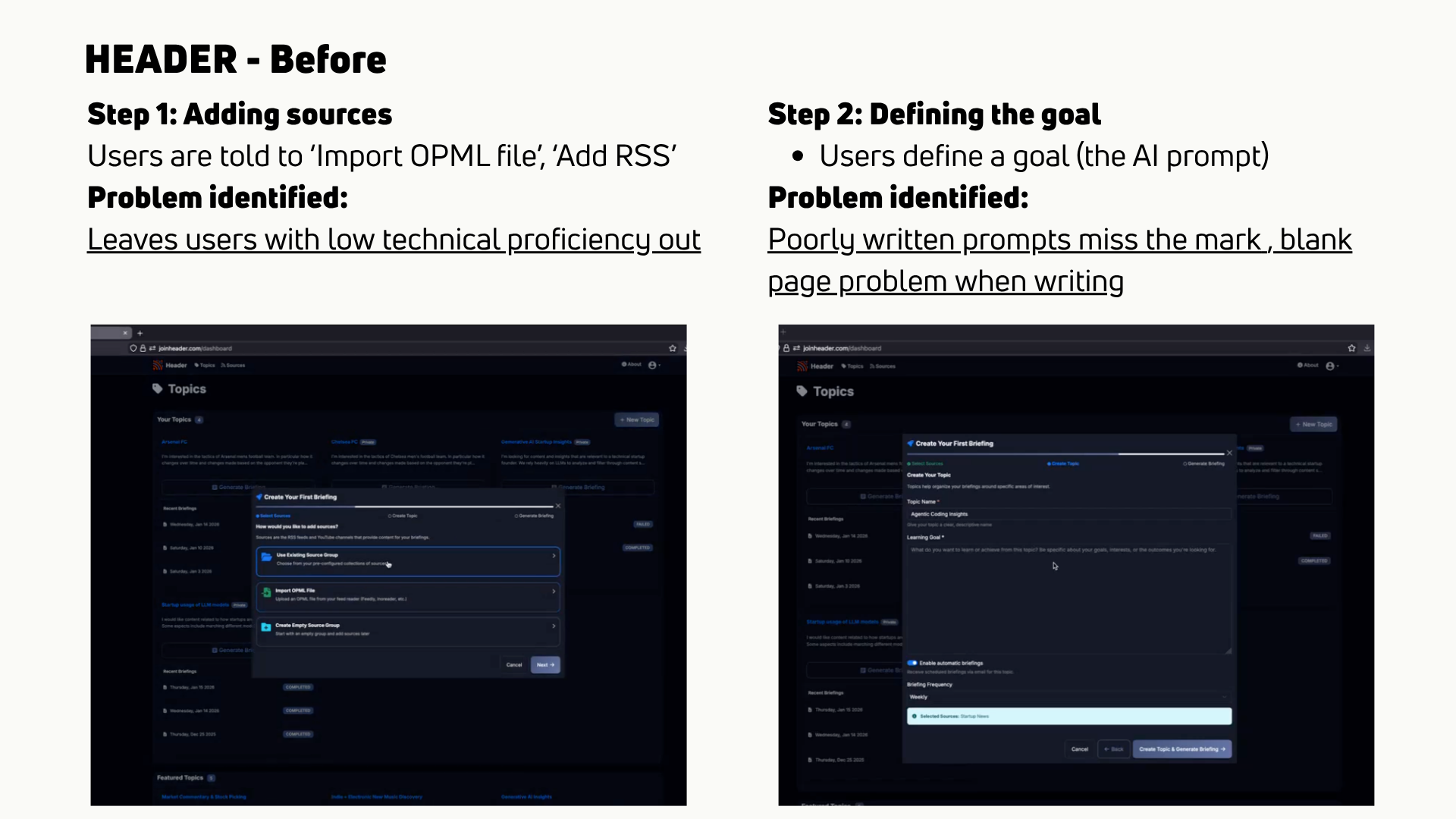
- Pauses and confusion during prompt writing and source selection. Users with limited AI exposure stalled at the blank prompt. Users with limited content-aggregation experience did not know what to do with the source field.
- Source format errors. Users tried to add YouTube and blog links directly, then discovered the field expected RSS, then often gave up.
- Failed briefings. Briefings generated from poor prompts or wrong sources at times came back irrelevant, or thin. Users didn’t get much value out of them.
I defined three metrics from those signals that the engineering team adopted: briefing success rate (how informative/useful did the users think it was), source-add success rate (successfully added sources), and use frequency and topic breadth (briefings per user, distinct topics tracked).
I presented findings to the co-founders with specific product recommendations rather than as research reports. Three shipped in tight succession:
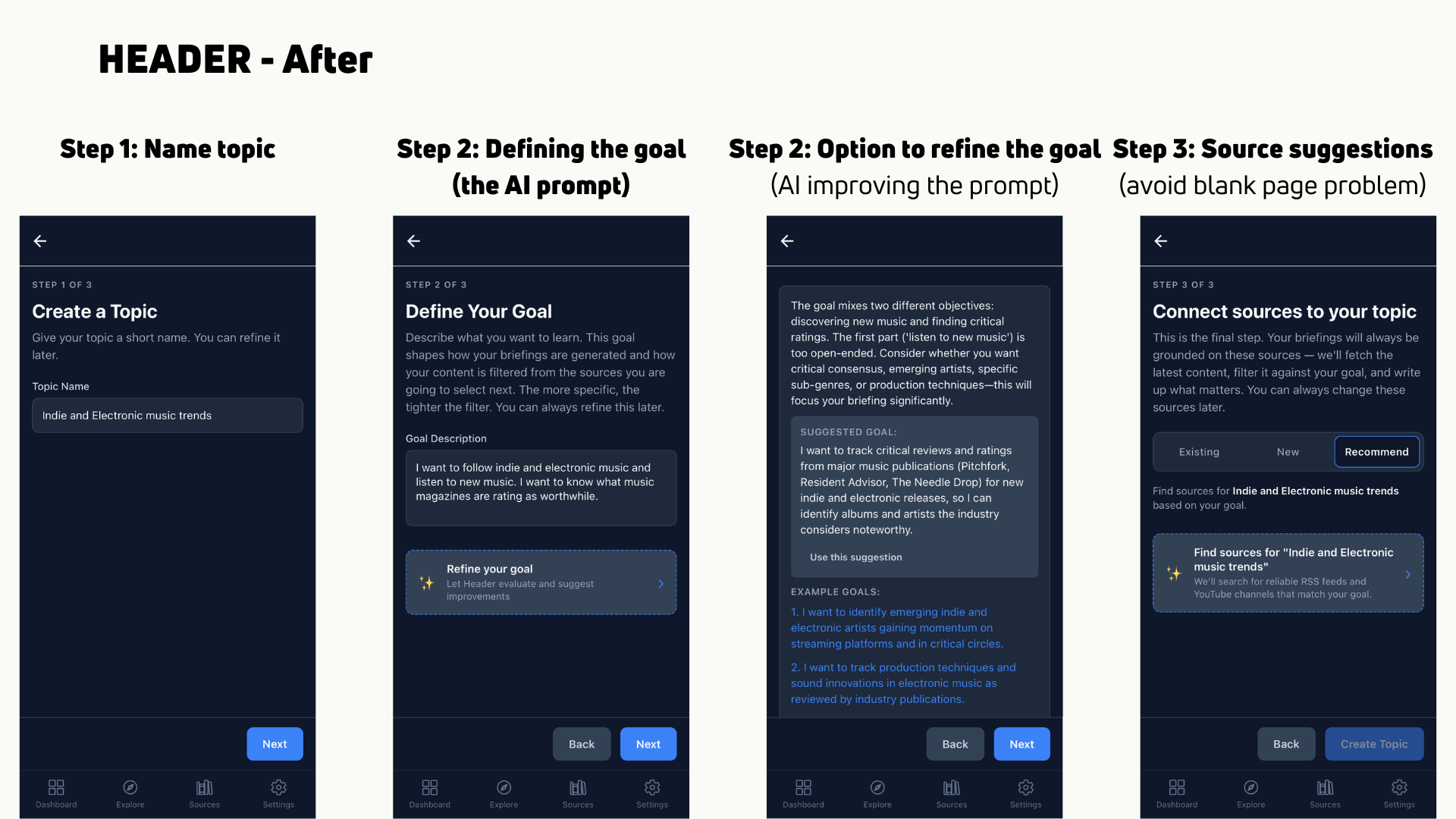
- AI-assisted prompt revision. A one-click “improve this prompt” affordance that let users skip the blank-page problem, and review what aspects of the initial prompt could cause issues.
- Source recommender. After a user describes a topic and goal, Header suggests sources to choose from. This eliminated the hardest part of the first-time experience.
- Follow-anything source input. Users can now paste any URL instead of finding an RSS feed.
We later added a curated topics and public briefings gallery so new users have something concrete to look at before configuring anything. It functions as both a demo and a template store.
Result
The metrics framework is in active use. Among users with low prior AI exposure, the segment most affected by the friction we found, failed briefings dropped 25% and use frequency and topic breadth lifted 30%, measured by retesting two weeks after the changes shipped against the equivalent two-week baseline.
The three product changes I recommended (prompt assist, source recommender, link-based input) are all in the current product, along with the public briefings gallery.
User segment and method fit
I deliberately did not segment recruitment by AI literacy at the start. I wanted to see what worked broadly and what did not, and let the segments emerge from the data. I found that prior working knowledge of AI-assisted tools split the user base more cleanly than age, role, or industry.
Once that pattern surfaced, I framed product changes around supporting the lower-AI-literacy segment without degrading the experience for the technical early users.
I used a mixed-methods approach (observation + survey + log analysis) because Header was early enough that we needed to catch unexpected friction and also see what metrics we need to keep tracking after the intial studies ended.
What I would do differently
Now that the product is more mature, I would start a similar engagement with a “what would you build” prompt before introducing the existing product. I would ask participants to sketch or vibecode their own version first; this would reveal which features they consider essential.